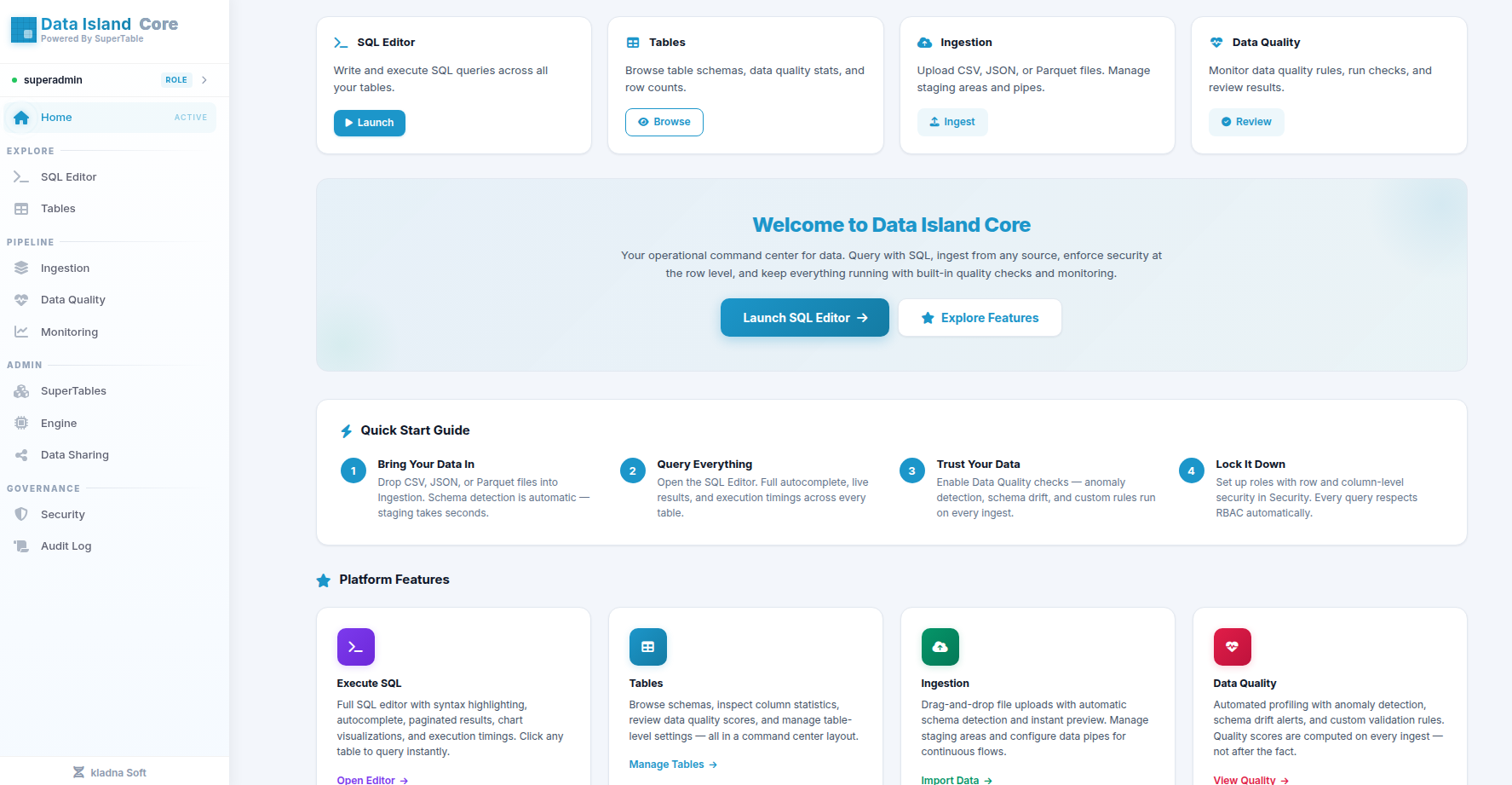
The Data Island Platform
A four-layer architecture engineered for versioned storage, zero-trust security, developer productivity, and AI-native intelligence.
Versioned lakehouse + agentic AI workbench.
One platform, two surfaces. SQL-first storage for engineers and BI, natural-language reasoning for everyone else — sharing the same data, the same RBAC, the same audit trail.
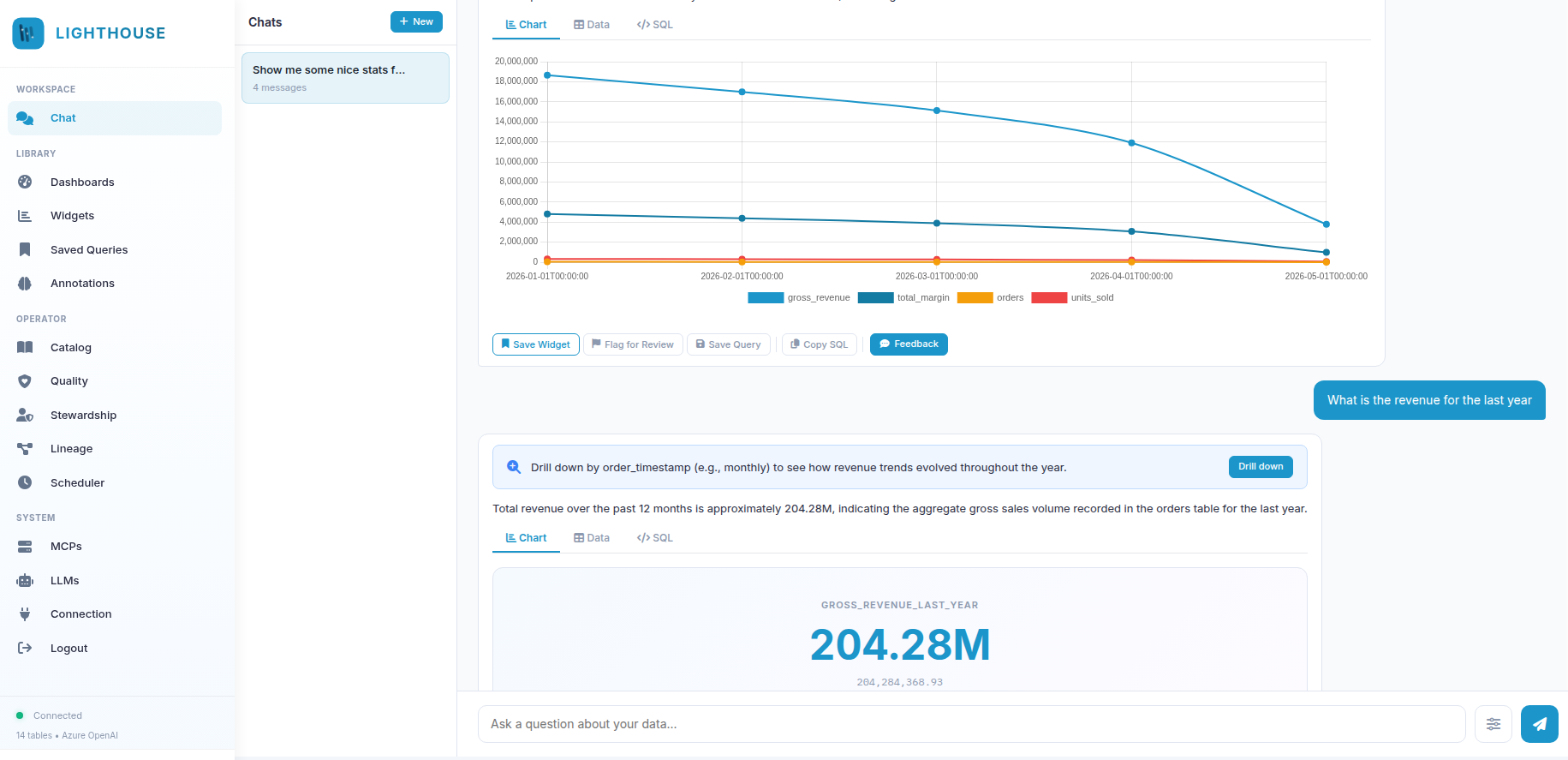
AI integration in BI and pipelines is hard. We cracked it.
For ten years every vendor has promised "AI on top of your warehouse" and shipped a chatbot bolted to a database. Lighthouse is the first agentic workbench that lives inside the platform — same RBAC, same audit, same data — not a third-party SaaS slurping your tables.
AI that reasons over your data
Lighthouse runs a 7-step agentic pipeline — understand → catalog_match → pattern → sql_gen → query_sql → data_analyze → anomaly_check — and routes each step to the best LLM with automatic fallback. Every claim traces back to a real value: no hallucinated numbers.
Conversational BI — beyond dashboards
Ask in English, get a chart, the SQL, and an explanation. Save as widgets, compose into dashboards, schedule recurring reports. Power BI and Excel still plug in via OData 4.0 for the dashboards that already exist.
LighthouseData quality that proposes its own rules
The Quality workbench profiles every table, narrates drift, hunts anomalies, and compiles plain-English rules ("never let gross_margin go negative") into structured constraints. A copilot for every steward.
LighthouseData Silos
Marketing has spreadsheets, engineering has a lake, finance has a warehouse. Data Island unifies every team under one platform with organizational isolation.
Compliance Burden
DORA, SOC 2, and GDPR demand immutable audit trails and fine-grained access control. Data Island ships these built-in — not bolted on. Lighthouse inherits the same RBAC and audit trail at no extra cost.
Vendor Lock-In
Proprietary formats, egress fees, rewritten pipelines. Data Island stores standard Parquet on any backend and mirrors to Delta Lake and Iceberg. Lighthouse runs on your infrastructure with your choice of LLM provider.
Data Loss Risk
Bad UPDATEs and accidental DELETEs silently destroy data. Append-only versioned storage preserves every historical state — nothing is ever lost.
Prompts that leak data
Generic AI tools ship your tables to a third-party SaaS. Lighthouse sends column names + types, never row data, and the LLM router lets you swap to a self-hosted model with one config change. Your data stays where it belongs.
Four Layers. Complete Data Platform.
Each layer is independently deployable, fully API-driven, and purpose-built for its domain.
Next-Generation BI, Built In
Layer 4 — Lighthouse — turns the platform into an agentic system. The modern replacement for clickable dashboards: ask in English, get a grounded answer, and the system learns from every interaction.
From clickable dashboards to natural-language reporting.
- Agentic, not just chat. A 7-step pipeline reasons across catalog, joins, and quality rules before answering — each step routed to the best LLM for the job, with automatic fallback.
- Grounded LLM analysis. Every claim traces back to a real value in your data. System prompts forbid invention; quality narrations cite actual null rates, drift, and anomalies.
- Data Chat reporting. Ask in English; get a chart, the SQL, and an explanation. Save as widgets, compose into dashboards, schedule as recurring reports.
- It learns over time. Feedback teaches the pipeline; typed annotations on the master MCP persist across operators, sessions, and restarts.
How the Layers Connect
Data flows through the platform in a clear, auditable path from ingestion to insight.
Write Path
Client Request
Application sends data via REST API, Python SDK, or bulk upload. Every request carries a JWT token.
Gatekeeper Validates
Token is verified against JWKS, permissions resolved. RBAC checks ensure the caller has Write permission on the target table.
Core Processes
Data is validated against the table schema, deduplicated, compressed to Parquet, and written as an immutable version to object storage.
Catalog Updated
Redis catalog records the new version with metadata: row count, byte size, schema hash, and SHA-256 audit hash chained to the previous entry.
Read Path
Query Arrives
SQL query comes in via REST, OData, MCP, or the WebUI. Token carries the caller's identity and roles.
View Chain Applied
Base data passes through the view chain: Dedup View → Tombstone View → RBAC View (row/column filtering) → User Query.
Engine Selected
Query engine auto-selects: DuckDB Lite for small datasets, DuckDB Pro with caching for medium, Spark SQL via Thrift for large workloads.
Results Returned
Filtered, authorized results are returned as JSON, OData, or streamed Parquet. The query is audit-logged with latency and row count.
Built-in Capabilities
Everything you need to store, query, govern, and share data — shipped as one platform, not assembled from parts.
Versioned Storage
Every write creates an immutable snapshot. Point-in-time queries across full history.
SQL Editor
Built-in web editor with auto engine selection — DuckDB for speed, Spark for scale.
RBAC
Five permission tiers with table, row, and column-level security filters.
Audit Logging
Tamper-evident SHA-256 hash chains. 21 structured fields. 7-year retention.
Staging & Ingestion
Two-phase ingestion — stage, review, then commit. Parquet, CSV, and SDK inserts.
OData 4.0
Power BI, Excel, and Tableau connect with a URL and bearer token. No drivers.
MCP Server
24 tools for Claude Desktop, Cursor, and MCP-compatible AI assistants.
Data Sharing
Zero-copy cross-org sharing with column and row filters. Instant revocation.
Table Mirroring
Auto-export to Delta Lake, Iceberg, and Parquet after every write.
Data Quality
16 built-in checks, 5 anomaly detectors, quality scores with trend analysis.
Monitoring
Read/write metrics, latency breakdowns, active instances, and service health.
Multi-Cloud
S3, Azure, GCS, MinIO, local disk. Switch backends via config — no migration.
Deploy Your Way
From an embedded Python install to a full Docker Compose stack with orchestrated profiles. Production-ready from day one.
pip install
Install the Python SDK for embedded use, scripting, and CI/CD pipelines. Full API access without Docker.
pip install supertableDocker Compose
Bring up infrastructure and services together with Compose profiles. Production-ready: orchestrated start order, health checks, and isolated networks.
docker compose --profile infra --profile services up -dTechnology Stack
Built on proven, open-source foundations. No vendor lock-in.
| Component | Technology | Purpose |
|---|---|---|
| Runtime | Python 3.10+ |
Core language for all services |
| API Framework | FastAPI |
Async REST API with auto-generated OpenAPI docs |
| Catalog & Cache | Redis |
Metadata catalog, session store, pub/sub cache invalidation |
| SQL Engine (small) | DuckDB |
In-process OLAP for sub-second analytics |
| SQL Engine (large) | Apache Spark |
Distributed SQL via Thrift for large-scale workloads |
| Data Format | Apache Parquet |
Columnar storage with compression and predicate pushdown |
| DataFrame Engine | Polars |
High-performance Rust-backed dataframe processing |
| Interoperability | Delta Lake / Iceberg |
Table mirroring for Spark, Databricks, Snowflake ecosystem |
| Object Storage | S3 / Azure / GCS / MinIO |
Pluggable multi-cloud storage backends |
| Encryption | Fernet (AES-128-CBC) |
Symmetric encryption at rest for sensitive catalog data |
Built for Every Data Role
One platform, five workflows — from engineering to compliance to AI-assisted analytics.
Data Engineers
Build & IngestWrite with the Python SDK, query with SQL. The platform handles schema evolution, dedup, and storage optimization — no Spark cluster to manage.
Compliance Officers
Audit & GovernanceImmutable audit trails with SHA-256 hash chains, row- and column-level access control, and 7-year log retention. Built for DORA, SOC 2, and GDPR.
BI Analysts
Analyze & VisualizeConnect Power BI or Excel directly via OData. Live dashboards against production data — no waiting for engineers to build ETL pipelines.
AI / ML Teams
Reason & AutomateConnect Claude Desktop or Cursor via MCP. Query tables, explore schemas, and profile columns through natural-language conversation.
Platform Builders
Scale & IntegrateMulti-org isolation, cross-org data sharing, and open-format mirroring for Spark, Databricks, and dbt ecosystem interoperability.
Decision Makers
Control & SovereigntyOwn the data layer end-to-end. No phone-home, no per-query egress, no vendor lock-in — sovereign infrastructure with a transparent license.